
Data 관점으로 Process 바라보기
MySQL에서 PostgreSQL의 ROW_NUMBER(), DENSE_RANK(), RANK() 함수 기능과 동일한 SQL 작성하기 본문
데이터,DB/SQL
MySQL에서 PostgreSQL의 ROW_NUMBER(), DENSE_RANK(), RANK() 함수 기능과 동일한 SQL 작성하기
얌스러운얌얌 2020. 11. 19. 20:27
PostgreSQL의 ROW_NUMBER(), DENSE_RANK(), RANK() 함수는 때때로 유용하게 사용할 수 있다.
Oracle, MS-SQL 등의 상용 DBMS에서도 동일하거나 비슷한 함수와 문법으로 기능을 제공하고 있다.
하지만, MySQL 5.x 버전까지는 해당 기능을 수행하는 함수를 제공하지 않는다.
(MySQL 8.x 버전에는 해당 함수들이 추가되었다.)
그래서 조금 복잡하지만, 변수 기능을 활용해서 SQL을 작성해야 한다.
테스트용 Table 및 데이터 생성
/** for PostgreSQL */
CREATE TABLE test.emp (
empno INT,
ename VARCHAR(30),
job VARCHAR(30),
sal INT
);
INSERT INTO test.emp
VALUES (7844, 'TURNER', 'SALESMAN', 1500),
(7369, 'SMITH', 'CLERK', 800),
(7698, 'BLAKE', 'MANAGER', 2850),
(7654, 'MARTIN', 'SALESMAN', 1250),
(7876, 'ADAMS', 'CLERK', 1100),
(7566, 'JONES', 'MANAGER', 2975),
(7788, 'SCOTT', 'ANALYST', 3000),
(7934, 'MILLER', 'CLERK', 1300),
(7782, 'CLARK', 'MANAGER', 2450),
(7521, 'WARD', 'SALESMAN', 1250),
(7839, 'KING', 'PRESIDENT', 5000),
(7902, 'FORD', 'ANALYST', 3000),
(7900, 'JAMES', 'CLERK', 950),
(7499, 'ALLEN', 'SALESMAN', 1600);/** for MySQL */
CREATE TABLE emp (
empno INT,
ename VARCHAR(30),
job VARCHAR(30),
sal INT
) ENGINE = INNODB
DEFAULT CHAR SET = UT8F;
INSERT INTO emp
VALUES (7844, 'TURNER', 'SALESMAN', 1500),
(7369, 'SMITH', 'CLERK', 800),
(7698, 'BLAKE', 'MANAGER', 2850),
(7654, 'MARTIN', 'SALESMAN', 1250),
(7876, 'ADAMS', 'CLERK', 1100),
(7566, 'JONES', 'MANAGER', 2975),
(7788, 'SCOTT', 'ANALYST', 3000),
(7934, 'MILLER', 'CLERK', 1300),
(7782, 'CLARK', 'MANAGER', 2450),
(7521, 'WARD', 'SALESMAN', 1250),
(7839, 'KING', 'PRESIDENT', 5000),
(7902, 'FORD', 'ANALYST', 3000),
(7900, 'JAMES', 'CLERK', 950),
(7499, 'ALLEN', 'SALESMAN', 1600);
기본 조회
/** for PostgreSQL, MySQL */
SELECT E.*
FROM test.emp AS E
ROW_NUMBER()
/** for PostgreSQL */
SELECT E.*, (ROW_NUMBER() OVER ()) AS row_num
FROM test.emp AS E/** for MySQL */
SELECT E.*, (@ROW_NUM := @ROW_NUM + 1) AS row_num
FROM emp AS E, (SELECT @ROW_NUM := 0) AS R0
ROW_NUMBER() OVER( PARTITION BY ... ORDER BY ... )
/** for PostgreSQL */
SELECT E.*, (ROW_NUMBER() OVER (PARTITION BY E.job ORDER BY E.sal)) AS row_num
FROM test.emp AS E/** for MySQL */
SELECT E.empno, E.ename, E.job, E.sal, E.row_num
FROM (SELECT E0.*,
IF(@PREV_JOB = E0.job, @ROW_NUM := @ROW_NUM + 1, @ROW_NUM := 1) AS row_num,
(@PREV_JOB := E0.job) AS _v_job
FROM emp AS E0, (SELECT @ROW_NUM := 0, @PREV_JOB := '') AS P0
ORDER BY E0.job, E0.sal
) AS E
DENSE_RANK() OVER( PARTITION BY ... ORDER BY ... )
/** for PostgreSQL */
SELECT E.*, (DENSE_RANK() OVER (PARTITION BY E.job ORDER BY E.sal)) AS row_num
FROM test.emp AS E/** for MySQL */
SELECT E.empno, E.ename, E.job, E.sal, E.row_num
FROM (SELECT E0.*,
IF(@PREV_JOB = E0.job AND @PREV_SAL = E0.sal, @ROW_NUM := @ROW_NUM,
IF(@PREV_JOB = E0.job, @ROW_NUM := @ROW_NUM + 1, @ROW_NUM := 1)) AS row_num,
(@PREV_JOB := E0.job) AS _v_job,
(@PREV_SAL := E0.sal) AS _v_sal
FROM emp AS E0, (SELECT @ROW_NUM := 0, @PREV_JOB := '', @PREV_SAL := 0) AS P0
ORDER BY E0.job, E0.sal
) AS E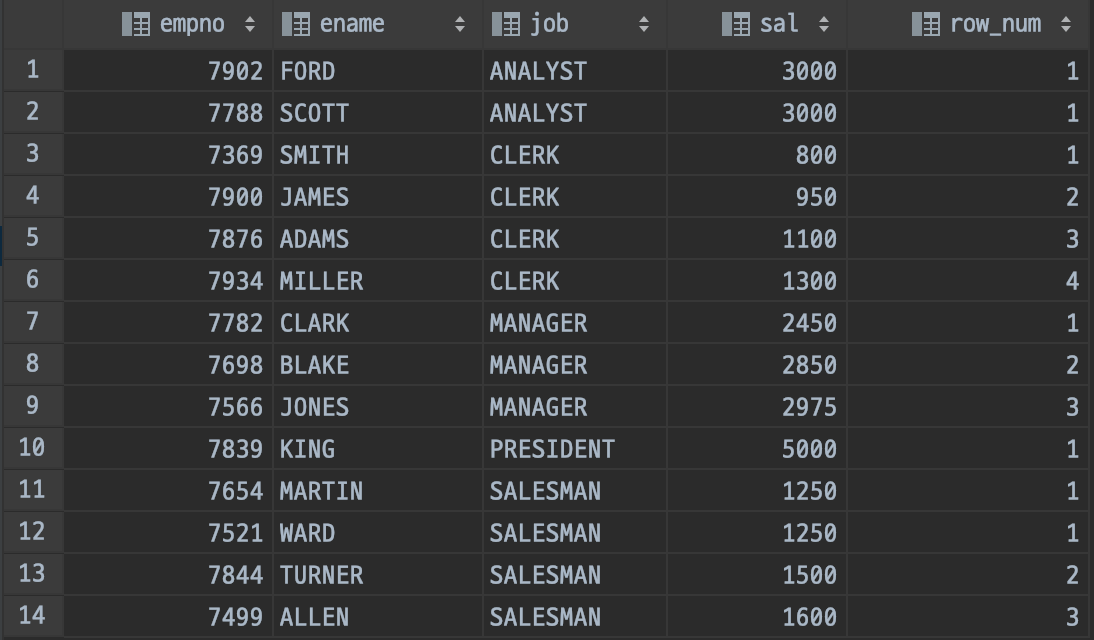
RANK() OVER( PARTITION BY ... ORDER BY ... )
/** for PostgreSQL */
SELECT E.*, (RANK() OVER (PARTITION BY E.job ORDER BY E.sal)) AS row_num
FROM test.emp AS E/** for MySQL */
SELECT E.empno, E.ename, E.job, E.sal, E.row_num
FROM (SELECT E0.*,
IF(@PREV_JOB = E0.job AND @PREV_SAL = E0.sal, @ROW_NUM := @ROW_NUM,
IF(@PREV_JOB = E0.job, @ROW_NUM := @ROW_NUM + 1, @ROW_NUM := 1)) AS row_num,
IF(@PREV_JOB = E0.job AND @PREV_SAL = E0.sal, @ROW_NUM := @ROW_NUM + 1,
@ROW_NUM := @ROW_NUM) AS _v_row_num,
(@PREV_JOB := E0.job) AS _v_job,
(@PREV_SAL := E0.sal) AS _v_sal
FROM emp AS E0, (SELECT @ROW_NUM := 0, @PREV_JOB := '', @PREV_SAL := 0) AS P0
ORDER BY E0.job, E0.sal
) AS E